Attributes:
te
lder
- simple Feedforward Network with one Layer
- cons: Global information not preserved --> GloVe
- cons: lacks broad context awareness --> solved by LSTMS, Transformers, GPT
- cons: Doenst work well for morphologically rich languages --> FastText
What is Word2Vec?
Word2Vec is a neural network-based language model that generates vector representations of words, known as word embeddings. These vectors capture the semantic meaning of words, enabling machines to understand the relationships between words in a high-dimensional space.
Technical Overview
Word2Vec consists of two main architectures:
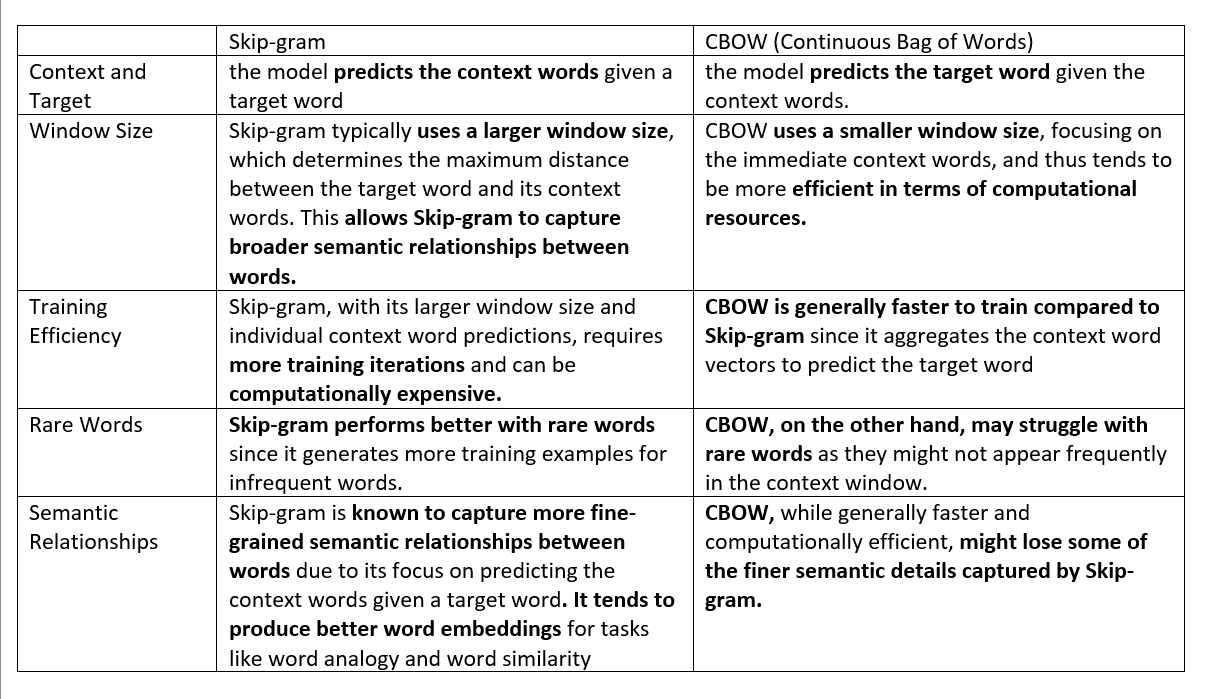
- Continuous Bag of Words (CBOW): Predicts a target word based on its context words.
- Skip-Gram: Predicts the context words based on a target word.
Both models are trained using a shallow neural network with a single hidden layer.
CBOW (Continuous Bag of Words) Model
Input: A window of context words (e.g., 5 words) surrounding a target word.
Hidden Layer: The input context words are fed into a fully connected neural network with a single hidden layer. The hidden layer has a smaller dimensionality than the input layer.
Output: The output is the predicted target word.
Training Objective: The model is trained to minimize the average log loss between the predicted word and the actual target word.
Skip-Gram Model
Input: A target word.
Hidden Layer: The input target word is fed into a fully connected neural network with a single hidden layer. The hidden layer has a smaller dimensionality than the input layer.
Output: The output is the predicted context words surrounding the target word.
Training Objective: The model is trained to minimize the average log loss between the predicted context words and the actual context words.
Word Embeddings
The hidden layer in both models learns to represent words as dense vectors in a high-dimensional space (typically 100-300 dimensions). These vectors, called word embeddings, capture the semantic meaning of words.
Key Properties of Word Embeddings
- Vector Space: Word embeddings exist in a vector space, enabling mathematical operations (e.g., addition, scalar multiplication) to capture semantic relationships.
- Similarity: Words with similar meanings are close together in the vector space.
- Analogy: Word embeddings preserve analogical relationships, such as "king - man + woman = queen".
Training
Word2Vec models are typically trained on large amounts of text data using stochastic gradient descent (SGD) or its variants. The training process involves:
- Tokenization: Breaking down text into individual words or tokens.
- Context Window: Defining a context window (e.g., 5 words) around each target word.
- Negative Sampling: Sampling negative examples (non-context words) to contrast with positive examples (context words).
- Optimization: Updating model parameters to minimize the loss function.
Applications
Word2Vec has numerous applications in NLP, including:
- Text Classification: Using word embeddings as input features for text classification tasks.
- Language Modeling: Predicting the next word in a sequence of text.
- Machine Translation: Translating text from one language to another.
- Question Answering: Answering questions based on the semantic meaning of words.
In conclusion, Word2Vec is a powerful technique for learning vector representations of words, enabling machines to understand the nuances of human language.