https://cvw.cac.cornell.edu/gpu-architecture/extras/quiz?sysr=667026c20c0e4
Lerneinheiten
que :: thread safe and process safe
pipe() :: is not thread safe
Lock() :: to lock a thread to protect data being accessed by another thread dead lock
Kafka
Was ist kafka? :: Ein Event Streaming Platform
Was sind Topics :: Topics sind named events, die man subscriben kann und publishen kann.
Aus was besteht ein Event? :: Timestamp; key-value; metadata
Wie heissen die Subscriber und publisher :: Producer / Consumer
Wie funktionieren Partitions in Kafka
?
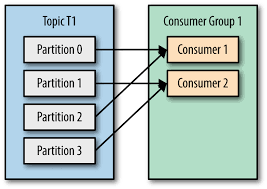 Kafka partitions a topic into multiple ordered logs to enable horizontal scaling and high throughput, with each partition replicated for fault tolerance. Consumers are grouped into consumer groups, where each partition is assigned to only one consumer in the group, ensuring parallel and efficient message processing. Offsets track the last processed message for fault tolerance, allowing consumers to resume from the last position in case of failures.
Kafka partitions a topic into multiple ordered logs to enable horizontal scaling and high throughput, with each partition replicated for fault tolerance. Consumers are grouped into consumer groups, where each partition is assigned to only one consumer in the group, ensuring parallel and efficient message processing. Offsets track the last processed message for fault tolerance, allowing consumers to resume from the last position in case of failures.
Slowing Factors
- Data dependencies --> forced sequential executiton
- statup time
- Bottlenecks
- Communication overhead
was heisst thread safety? :: No deadlocks in threads
GIL (Global Interpreter Locks) :: makes it thread safe, improves single thread performance, prevents simulatanios multithreading
Memory Usage
MPP :: Massive Parallel System
NOW :: Network of Workstations loosly coupled group of
ccNuma :: cache cohererent none uniform memory access
nccNUMA :: non-cc NUMA
COMA ::
LE 1
Zusammenfassung zur parallelen Programmierung und Flynnscher Taxonomie
Flynnsche Taxonomie in Data Science
SISD Beispiel in Data Science :: Ein einfaches Python-Skript, das eine Liste von Zahlen sequenziell durchläuft und deren Summe berechnet. (Single Instruction Single Input Data)
SIMD Beispiel in Data Science :: Die numpy Bibliothek, die Vektor-Operationen auf Arrays parallel ausführt. (Single Instruction Multiple Data)
MISD Beispiel in Data Science :: Fehlertoleranzsysteme, die mehrere Algorithmen auf dieselben Daten anwenden. (Multiple Instructions Single Data)
MIMD Beispiel in Data Science :: multiprocessing Modul in Python, wo verschiedene Prozesse unterschiedliche Aufgaben auf verschiedenen Daten ausführen. (Multiple Instructions Multiple Data)
threading in Flynnscher Taxonomie :: MIMD
multiprocessing in Flynnscher Taxonomie :: MIMD
numpy in Flynnscher Taxonomie :: SIMD
numba in Flynnscher Taxonomie :: SIMD
numba-cuda in Flynnscher Taxonomie :: SIMD
Roofline Model
?
The Roofline Model is a performance analysis tool used to visualize the limitations of computational tasks on a given hardware architecture. It plots performance (FLOPS) against operational intensity (FLOP per byte of memory access), with two key boundaries: the memory bandwidth and the peak computational throughput. The model helps identify whether a computation is bound by memory bandwidth or computational capacity. By analyzing where a task falls on the roofline graph, developers can focus optimization efforts on the correct bottleneck, either improving memory access patterns or enhancing computational efficiency.
Amdahl's Law und Gustafson's Law
Unterschied zwischen Amdahl's Law und Gustafson's Law
?
Amdahl's Law: Maximale Beschleunigung durch parallele Ausführung ist durch den seriellen Anteil begrenzt.
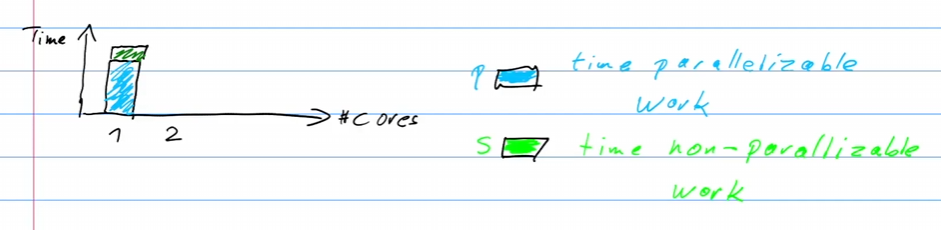

Gustafson's Law :: Der Problemumfang wächst mit der Anzahl der Prozessoren, wodurch parallele Effizienz höher bleibt. Der Serielle Teil bleibt bei der Gustafons Law constant.
Praxisbedeutung von Amdahl's Law
?
Nützlich zur Abschätzung der maximal erreichbaren Geschwindigkeitserhöhung bei gegebenem sequentiellem Anteil.
Praxisbedeutung von Gustafson's Law
?
Realistischere Einschätzung bei skalierenden Problemen, da größere Probleme mehr parallelisierbare Anteile haben.
Warum ist Gustafons Law und Ahmdals law nicht correct :: In fact, both laws when applied to modern parallel systems may be inaccurate since communication costs have large effects on speed up.
Klassische parallele Programmiermodelle
Datenparallelismus Beispiel
?
Verarbeitet große Datensätze parallel, z.B. MapReduce.
Aufgabenparallelismus Beispiel
?
Unabhängige Aufgaben werden parallel ausgeführt, z.B. asyncio in Python.
Pipeline-Parallelismus Beispiel
?
Aufgabensequenzen werden wie in einer Pipeline parallel verarbeitet, z.B. in Bildverarbeitungs-Workflows.
Leistung eines parallelen Programms
Speedup Definition
?
Verhältnis der Ausführungszeit des sequentiellen Programms zur parallelen Ausführungszeit.
Effizienz Definition
?
Verhältnis von Speedup zur Anzahl der Prozessoren.
Skalierbarkeit Definition
?
Wie gut das Programm mit zunehmender Anzahl von Prozessoren skaliert, gemessen durch Speedup und Effizienz bei unterschiedlichen Prozessoranzahlen.
Methoden zur Schätzung der Parallelisierbarkeit
Amdahl's Law Vorteil und Nachteil
?
Vorteil: Einfache Berechnung. Nachteil: Unterschätzt oft das Potential bei großen Problemgrößen.
Gustafson's Law Vorteil und Nachteil
?
Vorteil: Realistischere Annahmen für skalierende Probleme. Nachteil: Schwerer anwendbar für feste Problemgrößen.
Best Practices für parallele Anwendungen
Bottlenecks vermeiden
?
Minimierung serieller Anteile und Optimierung der Datenkommunikation.
Trade-Offs beachten
?
Zwischen Parallelisierungsaufwand und erzieltem Speedup.
Pitfalls vermeiden
?
Race Conditions und Deadlocks durch geeignete Synchronisationsmechanismen.
Parallele Muster in Data Science
MapReduce in Data Science :: Datenparallelismus; löst das Problem der Verteilung und Aggregation großer Datensätze.
Pipeline-Parallelismus in Data Science :: Befehlsparallelismus; löst das Problem der sequentiellen Datenverarbeitung in einer verteilten Umgebung.
CPU/GPU/Computing-bound vs. IO-bound
CPU/GPU/Computing-bound Bedeutung
?
Programme, deren Leistung durch die Rechenkapazität begrenzt ist. Beispiel: Training eines Deep Learning Modells.
IO-bound Bedeutung
?
Programme, deren Leistung durch Eingabe-/Ausgabeoperationen begrenzt ist. Beispiel: Datenbankabfragen in einem Data Warehouse.
Threads, Locks und Synchronisierung in Python
Threads Bedeutung
?
Kleinste Ausführungseinheiten in einem Prozess. Python nutzt das threading Modul.
Locks Bedeutung
?
Mechanismen zur Vermeidung von Race Conditions. Python bietet threading.Lock.
Allow only one thread at a time to access a resource
Synrochinze threads
Was ist eine Race condiditon
?
Zwei Threads die inkorrekt die shared resource accessen.
Synchronisierung Bedeutung
?
Koordination von Threads, um konsistente Datenzustände zu gewährleisten. Python bietet queue für Thread-Kommunikation.
Was macht Thread.join()
?
Wartet bis der Thread beended ist
Warum sollte man den ThreadPoolExecuter als context Manager verwenden?
?
Weil er alle threads startet und warted bis alle fertig sind.
Threading in Python Quiz
Row-major Struktur Bedeutung
?
Daten werden zeilenweise gespeichert. Standard in C, C++.
Column-major Struktur Bedeutung
?
Daten werden spaltenweise gespeichert. Standard in Fortran, Matlab.
Synchrone vs. asynchrone Programmierung
Synchrones Programmieren Bedeutung
?
Aufgaben werden sequenziell abgearbeitet. Vorteil: Einfach zu implementieren und debuggen. Nachteil: Kann ineffizient sein bei IO-gebundenen Aufgaben.
Asynchrones Programmieren Bedeutung
?
Aufgaben werden nebenläufig bearbeitet. Vorteil: Effiziente Nutzung von Ressourcen bei IO-gebundenen Aufgaben. Nachteil: Komplexer zu implementieren und debuggen.
LE 2
Zusammenfassung zu Docker Containern und Clustern
Docker Containers
Docker Image vs. Docker Container
Unterschied zwischen Docker und VM :: Docker benutzt den selbern Kernel wie das Betriebsystem braucht also kein Gastbetriebsystem. Docker Container sind kein vollwertiges Betriebsystem.
Was sind die Unterschiede zwischen einem Docker Image und einem Docker Container?
?
Docker Image: Ein unveränderbares Blueprint für Container, enthält alle notwendigen Dateien und Konfigurationen.
Docker Container: Eine laufende Instanz eines Docker Images, die eine isolierte Umgebung bietet.
Wie werden Docker Images und Docker Container benutzt?
?
Docker Image: Erstellen mit docker build, speichern und verteilen.
Docker Container: Starten und verwalten mit docker run, docker stop, docker rm.
Layers eines Docker Images
Was sind konkrete Beispiele für die Layers eines Docker Images?
?
Beispiele:
FROM ubuntu:latestRUN apt-get update && apt-get install -y python3COPY . /app
Wie werden die Layers definiert?
?
Layers werden durch Anweisungen im Dockerfile definiert (z.B. FROM, RUN, COPY).
Mit welchem Kommando können die Layers angezeigt werden?
?
docker history <image_name>
Docker Registry
Welches ist die Default-Registry von Docker?
?
Docker Hub
Vor- und Nachteile der Default-Docker-Registry
?
Vorteile: Einfach zu verwenden, große Community und viele verfügbare Images.
Nachteile: Begrenzter kostenloser Speicherplatz, öffentlich zugängliche Images sind standardmäßig sichtbar.
Wie ist eine Registry aufgebaut (Komponenten)?
?
Komponenten:
- Registry: Speichert Images.
- Index: Verzeichnis der Images.
- Web UI: Verwaltung und Durchsuchung der Images.
Welche andere Arten von Docker-Registries gibt es? Beispiele?
?
Andere Registries:
- Amazon ECR (Elastic Container Registry)
- Google Container Registry
- Harbor
- Quay.io
Wie werden diese Komponenten in der Kommandozeile aufgerufen?
?
Beispiele:
- Login:
docker login - Push:
docker push <registry>/<image> - Pull:
docker pull <registry>/<image>
Docker Engine
Welche Aufgabe übernimmt die Docker Engine (im Dockerfile)?
?
Docker Engine: Führt die Anweisungen im Dockerfile aus und erstellt Images. Sie verwaltet Container und ihre Laufzeitumgebung.
Was vereinfacht die Docker Engine im Vergleich zu anderen Virtualisierungssystemen?
?
Vereinfachungen: Schnellere Startzeiten, weniger Overhead, einfache Verteilung und Skalierbarkeit.
Microservices in Containern
Wie können Microservices (Programm Module) in Containern abgebildet werden?
?
Microservices in Containern: Jedes Microservice wird in einem eigenen Container betrieben, wodurch Isolation und Skalierbarkeit verbessert werden.
Beispiele für Microservices in Containern?
?
Beispiele:
- Ein Webserver in einem Container (
nginx). - Eine Datenbank in einem anderen Container (
mysql).
Vor- und Nachteile der Containerisierung
Was sind die Vor- und Nachteile von Containerisierung?
?
Vorteile:
- Portabilität
- Konsistenz über Umgebungen
- Isolierung
- Effizienz
Nachteile: - Sicherheitsbedenken
- Komplexität beim Management vieler Container
- Netzwerk-Overhead
Clusters
Best Practices für parallele Anwendungen
Was sind Best Practices für Benutzer von parallelen Anwendungen auf einem Computing Cluster?
?
- Bottlenecks identifizieren und vermeiden
- Effiziente Ressourcennutzung
- Workload-Management
- Code-Optimierung für Parallelität
Performance-Analyse
Welche Mittel zur Performance-Analyse lokal sowie auf dem Cluster eignen sich? Unterschiede und Anwendungsszenarien?
?
- Lokal:
perf,gprof,valgrind - Cluster:
MPI,SLURM,Ganglia
Unterschiede:
- Lokal: Detaillierte Analyse einzelner Prozesse.
- Cluster: Skalierbarkeit und Management verteilter Systeme.
Performance-Bottlenecks
Welche Performance-Bottlenecks sind IO-bound bzw. CPU/Computing-bound?
?
- IO-bound: Langsame Festplattenzugriffe, Netzwerklatenz.
- CPU-bound: Intensive Rechenoperationen, unoptimierte Algorithmen.
PaaS vs. CaaS
Was sind die Unterschiede zwischen Plattform-as-a-Service (PaaS) und Container-as-a-Service (CaaS) Frameworks? Beispiele?
?
- PaaS: Bietet eine vollständige Entwicklungs- und Laufzeitumgebung. Beispiel: Heroku, Google App Engine.
- CaaS: Bietet Container-Management und -Orchestrierung. Beispiel: Google Kubernetes Engine, Amazon ECS.
Apache Kafka
Kommunikationsmuster in Apache Kafka
Welche Kommunikations-, Parallelisierungs- und Softwaremuster und Taxonomien werden in Apache Kafka verwendet?
?
Muster:
- Publish-Subscribe
- Message Queue
Was sind die Konzepte der typischen Komponenten in einem Kafka Cluster? Welche Komponenten gibt es?
?
Komponenten:
- Broker: Verteilt Nachrichten.
- Producer: Sendet Nachrichten.
- Consumer: Empfängt Nachrichten.
- Zookeeper: Verwalter der Kafka-Metadaten.
Implementierung eines Kafka-Clusters
Mittels welchem Pattern ist ein Kafka-Cluster umgesetzt? Welche weiteren Topologien kennst du?
?
Pattern: Publish-Subscribe.
Weitere Topologien:
- Point-to-Point
- Fan-out
Vor- und Nachteile der Communication Patterns
Was sind die Vor- und Nachteile der unterschiedlichen Communication Patterns?
?
- Publish-Subscribe
Vorteile: Skalierbarkeit, Entkopplung von Sender und Empfänger.
Nachteile: Komplexität bei der Verwaltung großer Datenströme. - Message Queue
Vorteile: Einfachheit, garantierte Zustellung.
Nachteile: Potenzielle Engpässe, weniger flexibel.
CSCS Cluster (optional)
Unterschiede zwischen Piz Daint und Grand Tave
Spezifiziere die Unterschiede zwischen den CSCS Computing Ressourcen Piz Daint und Grand Tave. Wofür wird welches Cluster eingesetzt?
?
- Piz Daint: Hochleistungsrechner für wissenschaftliche Berechnungen.
- Grand Tave: Unterstützt datenintensive Anwendungen und Analysen.
Slurm Job auf CSCS Cluster submitten
Wie submitte ich einen Slurm Job auf einem CSCS Cluster?
?
Verwenden von sbatch Kommando mit einem Slurm-Skript.
Output- und Errorlog eines Jobs finden
Wie finde ich das Output- sowie Errorlog meines Jobs und finde darin relevante Informationen?
?
Verwenden von sacct und Durchsuchen der .out und .err Dateien.
Filesysteme und deren Nutzung
Welche Filesysteme werden für was gebraucht?
?
- Lustre: Für hochperformante, parallele Dateizugriffe.
- NFS: Für geteilte Verzeichnisse und weniger intensive IO-Operationen.
Technisches Reporting auf dem CSCS Cluster
Wie funktioniert ein technisches Reporting auf dem CSCS Cluster?
?
Verwendung von Tools wie sreport und sacct zur Generierung von Leistungsberichten und Job-Statistiken.
LE 3
Beschleunigung in Data Science mit Python
Probleme der Parallelisierung/Beschleunigung in Python
Was sind die Probleme von Parallelisierung/Beschleunigung einer Sprache wie Python?
?
- Global Interpreter Lock (GIL): Verhindert echte Parallelität in Threads, da nur ein Thread zur gleichen Zeit Python-Bytecode ausführen kann.
- Overhead durch Interpreted Language: Python ist langsamer als kompilierte Sprachen wie C/C++ aufgrund der Interpretationsschicht.
- Speicherverwaltung: Dynamische Typisierung und automatische Speicherbereinigung können zu unerwarteten Speicherzugriffen und -verwaltungen führen, die die Leistung beeinträchtigen.
- Bibliothekenkompatibilität: Einige Python-Bibliotheken unterstützen keine parallele Ausführung oder sind nicht thread-safe.
Overhead von Python
Was ist der Overhead von Python?
?
- Interpreted Language Overhead: Langsamer als kompilierte Sprachen, da Code zur Laufzeit interpretiert wird.
- Speicherverwaltung: Automatische Speicherverwaltung und dynamische Typisierung verursachen zusätzlichen Overhead.
- GIL: Erhöht den Overhead, indem er echte Thread-Parallelität verhindert.
Beschleunigung von Python
Wie und wann kann Python beschleunigt werden?
?
- Vektorisierung: Nutzung von Bibliotheken wie NumPy und SciPy zur Durchführung von Array-Operationen, die in C implementiert sind.
- Just-in-Time (JIT) Compilation: Verwendung von Tools wie Numba, die Python-Funktionen zur Laufzeit kompilieren.
- Parallelisierung: Nutzung von Multiprocessing oder Dask zur parallelen Ausführung von Prozessen.
- C-Extensions: Implementierung von kritischen Codeteilen in C/C++ und deren Einbindung in Python.
- Speicheroptimierung: Profiling und Optimierung des Speichermanagements, um Speicherzugriffe zu minimieren.
Wann macht es Sinn, einen Codeteil in einer anderen (Hardware-näheren) Programmiersprache zu implementieren?
?
- Rechenintensive Aufgaben: Wenn Python zu langsam ist und Performance ein kritischer Faktor ist.
- Echtzeitanforderungen: Wenn die Latenzzeit entscheidend ist und schnelle Ausführung notwendig ist.
- Ressourcenintensive Algorithmen: Wenn der Speicherverbrauch und die Effizienz optimiert werden müssen.
Varianten der Beschleunigung in Python
Welche Varianten der Beschleunigung gibt es in Python? Und wofür eignen sie sich?
?
- Vektorisierung mit NumPy/SciPy:
Eignung: Mathematische und wissenschaftliche Berechnungen. - Just-in-Time Compilation mit Numba:
Eignung: Funktionen, die viele Schleifen und mathematische Operationen enthalten. - Parallelisierung mit Multiprocessing/Dask:
Eignung: Datenverarbeitung, die parallelisiert werden kann. - C-Extensions (Cython, F2PY, CFFI):
Eignung: Kritische Codeabschnitte, die eine signifikante Leistungssteigerung benötigen. - Profiling und Memory Management:
Eignung: Identifizierung und Optimierung von Engpässen und Speicherverbrauch.
NumPy/SciPy Vektorisierung:
?
Nutzung von voroptimierten Funktionen, die in C implementiert sind, um schnelle Array-Operationen durchzuführen.
Numba JIT Compilation:
?
Kompliliert Python-Funktionen zur Laufzeit in Maschinencode, wodurch die Ausführungsgeschwindigkeit erheblich erhöht wird.
Multiprocessing/Dask Parallelisierung:
?
Ermöglicht die parallele Ausführung von Aufgaben, indem mehrere Prozesse oder Threads verwendet werden.
Cython:
?
Ermöglicht das Schreiben von Python-Code, der in C kompiliert wird, um die Ausführungsgeschwindigkeit zu erhöhen.
F2PY:
?
Bietet eine Schnittstelle zur Integration von Fortran-Code in Python, um leistungsstarke numerische Berechnungen durchzuführen.
CFFI:
?
Ermöglicht die Einbindung von C-Bibliotheken in Python, um die Leistungsfähigkeit von C in Python zu nutzen.
Best Practices
Best Practices zur Beschleunigung von Python Code:
?
- Profiling: Identifizieren Sie Engpässe mit Tools wie
cProfileoderline_profiler. - Vektorisierung: Nutzen Sie Bibliotheken wie NumPy für vektorisierte Berechnungen.
- JIT Compilation: Verwenden Sie Numba für rechenintensive Funktionen.
- Parallelisierung: Nutzen Sie Multiprocessing oder Dask für Aufgaben, die parallel ausgeführt werden können.
- C-Extensions: Implementieren Sie kritische Teile des Codes in C oder C++.
- Speicheroptimierung: Minimieren Sie unnötige Speicherzuweisungen und -freigaben.
- Bibliothekenwahl: Verwenden Sie spezialisierte Bibliotheken, die für bestimmte Aufgaben optimiert sind.
LE 4
GPU-Programmierung in Python
Was ist der WARP :: Warp ist eine Sammlung von Threads 32 die simulatan executed werden by an Streamline Multiprocessor
Leistungsmessung von GPU-Programmen
Was muss bei der Leistungsmessung von GPU-Programmen berücksichtigt werden? Welche Teile sollten gemessen werden?
?
- Kernel-Ausführungszeit: Zeit, die der GPU-Kernel für die Ausführung benötigt.
- Datenübertragung: Zeit für das Kopieren der Daten zwischen CPU und GPU.
- Gesamtlaufzeit: Gesamte Ausführungszeit des Programms einschließlich Datenübertragung und Kernel-Ausführung.
Wie kann die Zeit des aufgerufenen GPU-Kernels gemessen werden?
?
Verwendung von CUDA-Events:
import cuda
start = cuda.event()
end = cuda.event()
start.record()
# Kernel aufrufen
end.record()
end.synchronize()
print('Kernel-Ausführungszeit: ', start.elapsed_time(end), 'ms')
Datenübertragung zur GPU
Wie sollten die Daten auf die GPU kopiert werden?
?
- Asynchrone Datenübertragung: Verwenden Sie asynchrone Kopiervorgänge, um die Übertragung zu überlappen.
- Paginierter Speicher: Nutzen Sie paginierten Speicher, um den Kopieraufwand zu minimieren.
- Pinned Memory: Verwenden Sie "Pinned Memory" für schnellere Datenübertragungen.
GPU-Speichertypen
Welche Speichertypen gibt es auf der GPU?
?
- Global Memory: Größter, aber langsamster Speicherbereich.
- Shared Memory: Schneller Zwischenspeicher, den Threads innerhalb eines Blocks gemeinsam nutzen.
- Registers: Schnellster Speicher, der von einzelnen Threads genutzt wird.
- Constant Memory: Speicher für konstante Werte, der von allen Threads gelesen werden kann.
- Texture Memory: Optimierter Speicher für Lesezugriffe.
Memory Coalescing
Was bedeutet Memory Coalescing?
?
Memory Coalescing bezieht sich auf die effiziente Speicherzugriffsoptimierung, bei der aufeinanderfolgende Threads auf aufeinanderfolgende Speicheradressen zugreifen, um Speicherbandbreite zu maximieren und Latenz zu minimieren.
Speicherzugriff durch Threads
Wie greifen Threads auf den Speicher zu? Z.B. nah oder weit voneinander entfernt innerhalb von Warp.
?
Nah beieinander: Threads eines Warp sollten auf benachbarte Speicheradressen zugreifen, um Coalescing zu ermöglichen und die Effizienz zu erhöhen.
Weit voneinander entfernt: Vermeiden Sie verstreute Zugriffe, da dies zu ineffizienten Speicherzugriffen führt und die Leistung beeinträchtigt.
Shared-Memory
Wann ist es sinnvoll, Shared-Memory zu benutzen?
?
Shared-Memory ist sinnvoll, wenn:
- Daten häufig zwischen Threads desselben Blocks ausgetauscht werden müssen.
- Wiederholte Zugriffe auf dieselben Daten notwendig sind.
- Reduzierung der globalen Speicherzugriffe zur Leistungsverbesserung.
Quiz
Beispielaufgaben
Leistungsmessung eines GPU-Kernels:
?
Nutzen Sie CUDA-Events, um die Ausführungszeit zu messen und analysieren Sie die Datenübertragungszeiten separat.
Datenübertragung auf die GPU optimieren:
?
Verwenden Sie asynchrone Datenübertragung und "Pinned Memory", um die Effizienz zu erhöhen.
Shared-Memory Nutzung:
?
Optimieren Sie Kernel, indem Sie häufig verwendete Daten in Shared-Memory speichern, um die globale Speicherzugriffe zu minimieren.
Memory Coalescing Beispiel:
?
Achten Sie darauf, dass aufeinanderfolgende Threads auf aufeinanderfolgende Speicheradressen zugreifen, um die Speicherzugriffseffizienz zu maximieren.
Summary
CPU to GPU
host: executed on the CPU
device: executed on the GPU
Kernels
CPU
Architecture:
Gloassary
SISD: Singgle Instruction Single Data
MISD: Multiple Instruction Single Data
SIMD: Single Instruction Multiple Data
MIMD: Multiple Instructions Multiple Data
Concurrent
Parrallel computations
Memory Allocations
- malloc --> Allocation of the Memory get the pointer.
Threads
Mutlit Processing
GPU
The GPU is specialized for highly parrallel computations, threads are having no overhead so switching between them doesnt cost any perfomance like on CPUs.
Blocks and Grids
/Pasted%20image%2020240617133029.png)
Blocks and Threads
1, 256 to 256, 1
32, 32
Clockcycles
Memory cleaning
- cudaFree(a_device)
Kernels
/Pasted%20image%2020240617125819.png)
- explain how Block indexes and Thread indexes works how you can compute in parallel
Memory allocation
Async Compuations
Wie sieht die Archiektur einer GPU aus
?
/Pasted%20image%2020240617141158.png)
CUDA
Wie kann man die Zeiten der Host2Device and Device2Host reduzieren:
?
/Pasted%20image%2020240613192251.png)
- Per se reduziert man nicht die Zeiten sondern spricht sie einfach concurrent aus in sogennanten Streams.
GPU-Programmierung: CUDA Streams
Grundkonzepte von CUDA Streams
Was ist ein CUDA Stream?
?
Ein CUDA Stream ist eine Sequenz von Operationen, die auf der GPU in der angegebenen Reihenfolge ausgeführt werden. Streams ermöglichen die gleichzeitige Ausführung mehrerer Aufgaben auf der GPU.
Wie werden CUDA Streams erstellt?
?
CUDA Streams werden mit der cudaStreamCreate-Funktion erstellt:
cudaStream_t stream;
cudaStreamCreate(&stream);
Verwendung von CUDA Streams
Wie führt man einen Kernel in einem bestimmten Stream aus?
?
Indem man den Stream als letzten Parameter bei der Kernel-Ausführung angibt:
kernel<<<gridSize, blockSize, 0, stream>>>(parameters);
Wie kopiert man Daten asynchron in einen CUDA Stream?
?
Verwenden Sie cudaMemcpyAsync, um Daten asynchron in einen Stream zu kopieren:
cudaMemcpyAsync(dest, src, size, cudaMemcpyHostToDevice, stream);
Vorteile von CUDA Streams
Warum sollten CUDA Streams verwendet werden?
?
CUDA Streams ermöglichen die gleichzeitige Ausführung von Berechnungen und Datenübertragungen, was die Effizienz und Leistung der GPU-Nutzung erhöht.
Was sind die Vorteile der Verwendung mehrerer CUDA Streams?
?
- Überlappung von Berechnungen und Datenübertragungen: Verbessert die Ressourcenauslastung.
- Erhöhte Parallelität: Mehrere unabhängige Aufgaben können gleichzeitig ausgeführt werden.
Synchronisierung von CUDA Streams
Wie synchronisiert man einen CUDA Stream?
?
Verwenden Sie cudaStreamSynchronize, um zu warten, bis alle Operationen in einem Stream abgeschlossen sind:
cudaStreamSynchronize(stream);
Wie kann man die Synchronisierung zwischen verschiedenen Streams sicherstellen?
?
Verwenden Sie Ereignisse (cudaEvent_t), um die Synchronisierung zwischen Streams zu kontrollieren:
cudaEvent_t event;
cudaEventCreate(&event);
cudaEventRecord(event, stream1);
cudaStreamWaitEvent(stream2, event, 0);
Best Practices für CUDA Streams
Welche Best Practices sollten bei der Verwendung von CUDA Streams beachtet werden?
?
- Minimieren Sie die Anzahl der Synchronisierungen: Übermäßige Synchronisation kann die Vorteile der Parallelität reduzieren.
- Verwenden Sie asynchrone Datenübertragungen: Dies ermöglicht die Überlappung von Datenübertragungen und Berechnungen.
- Optimieren Sie die Ressourcenzuweisung: Achten Sie darauf, dass genügend Ressourcen für die parallele Ausführung vorhanden sind.
Ich hoffe, diese Flashcards helfen Ihnen beim Verständnis und der Anwendung von CUDA Streams in Ihrer GPU-Programmierung!
etc.
Was heisst FLOPS :: Floating Points operations per second.
Amdahl's Law
Was ist das Amdahl's Law?
?
Die Beobachtung, dass die mögliche Beschleunigung eines parallelen Programms durch den Anteil der Berechnung begrenzt ist, der seriell ausgeführt werden muss. Der maximale mögliche Speedup S ist S = 1/((1-P) + P/N), wobei P der parallele Anteil und N die Anzahl der parallelen Threads ist.
Was bedeutet Allocation im Kontext von Computing-Ressourcen?
?
Eine Zuteilung von Rechenzeit, Speicherplatz oder anderen Arten von Rechenressourcen, die in der Regel dem Hauptforscher (PI) im Namen der von ihm geleiteten Forschungsgruppe gewährt wird.
Was ist Adaptive Mesh Refinement?
?
Eine Meshing-Technik, bei der ein feineres Gitter auf Bereiche eines groben Gitters überlagert wird, um die Auflösung in Bereichen mit steilen Gradienten zu verbessern. Die Korrektur wird entlang der grob-feinen Gittergrenzen angewendet, um die Erhaltungsgesetze des Systems zu wahren.
Was ist ein Bus
?
Data Transfersystem between Ram and CPU typically consisting of several lines
Bus-Width
?
Number of parallel data lines in a bus normally bit --> 64 or 32
GPU-Programmierung: Verwandte Begriffe
Synchronization (Multithreading)
Was ist Synchronization in Multithreading?
?
Die Verwendung eines Locks oder ähnlichen Mutex-Mechanismus, um sicherzustellen, dass keine zwei gleichzeitig ausgeführten Threads oder Prozesse denselben kritischen Abschnitt eines Programms zur gleichen Zeit ausführen. Threads müssen nacheinander diesen serialisierten Abschnitt des Programms ausführen, d.h., kein anderer Thread darf diesen Abschnitt ausführen, bis der aktuelle Thread fertig ist.
Task
Was ist ein Task in der Parallelprogrammierung?
?
Eine einzelne Instanz eines ausführbaren Programms in einem parallelen Programm. Eine übliche Methode zur Parallelisierung eines Programms besteht darin, seine Arbeit auf viele Tasks zu verteilen und die Tasks Knoten in einem Cluster zuzuweisen. Die Threads in jedem Task haben Zugriff auf einen virtuellen Adressraum, der für den Task einzigartig ist, sodass die Shared-Memory-Programmierung innerhalb eines Tasks verwendet werden kann.
Task Dependency
Was ist eine Task Dependency?
?
Eine Planungsbeschränkung, die entsteht, wenn eine Aufgabe, die möglicherweise parallel zu anderen Aufgaben ausgeführt werden könnte, nicht gestartet werden kann, bis eine oder mehrere der anderen Aufgaben abgeschlossen sind.
Task Graph
Was ist ein Task Graph?
?
Eine Darstellung eines Computerprogramms als gerichteter Graph, in dem die Knoten Aufgaben und die gerichteten Kanten Abhängigkeiten zwischen den Aufgaben darstellen. Die Parallelisierung des Programms entspricht der Partitionierung des Graphen.
TBB (Threading Building Blocks)
Was ist TBB?
?
Intel's C++-Template-Bibliothek zur Erstellung von Programmen, die die Vorteile von Multi-Core-Prozessoren nutzen.
Thread
Was ist ein Thread?
?
Ein Teil eines Prozesses (laufendes Programm), der eine Sequenz von Anweisungen ausführt. Er teilt sich einen virtuellen Adressraum mit anderen Threads im selben Prozess, hat jedoch seinen eigenen Anweisungszeiger und einen separaten Stack. Threads laufen unabhängig voneinander, daher muss eine Synchronisation explizit erfolgen, wenn sie erforderlich ist. Auf Multicore-Prozessoren plant das Betriebssystem Threads auf allen verfügbaren Ressourcen, sofern genügend Threads bereit sind.
Thread Safety
Was bedeutet Thread Safety?
?
Eine Eigenschaft, die sicherstellt, dass ein Stück Code oder eine Funktion korrekt funktioniert, wenn sie gleichzeitig von mehreren Threads ausgeführt wird.
Thread-Block
Was ist ein Thread-Block in CUDA?
?
Eine Gruppe von Threads, die gemeinsam an einem Array arbeiten, das von einer GPU verarbeitet wird. Die Operation wird durch eine CUDA-Kernfunktion definiert. Alle Threads im Block werden auf demselben GPU-SM (Streaming Multiprocessor) verarbeitet.
Throughput
Was ist Throughput?
?
Die Rate, mit der Daten verarbeitet oder Lösungen für ein gegebenes Problem von einem Rechensystem berechnet werden.
Thrust (GPU)
Was ist Thrust?
?
NVIDIA's High-Level-Parallel-Computing-Bibliothek für CUDA, die die C++-Standard-Template-Bibliothek (STL) imitiert.
Tiling
Was ist Tiling?
?
Eine Optimierungstechnik für bestimmte Matrixoperationen, auch als Blocking bezeichnet. Wenn eine NxN-Matrix in nxn-Blöcke oder Kacheln der Größe bxb unterteilt wird, sodass ein bxb-Block in einen Teil des Caches passt, wird die Datenwiederverwendung stark verbessert.
TLB (Translation Lookaside Buffer)
Was ist ein TLB?
?
Ein Cache physischer Adressen, den die Speicherverwaltungshardware verwendet, um die Geschwindigkeit der virtuellen Adressübersetzung zu verbessern. Alle aktuellen Desktop-, Notebook- und Serverprozessoren verwenden einen TLB zur Abbildung virtueller und physischer Adressräume. Ein TLB-Fehler führt zu einer langsamen Suche in der gesamten Seitentabelle.
Transistoren
Was sind Transistoren?
?
Die grundlegenden Bausteine eines integrierten Schaltkreises in einem Computerchip. Jeder Transistor ist ein winziges Halbleitergerät, das als Schalter oder Logikgatter fungiert. Mindestens ein Transistor wird benötigt, um ein Datenbit zu speichern; mehr sind erforderlich, wenn der Speicher nicht flüchtig ist.
Tree Decomposition
Was ist Tree Decomposition?
?
Eine Domänendekompositionstechnik, die zur adaptiven Gitterverfeinerung in simulierten Systemen verwendet wird, in denen die Datenpunkte dazu neigen, sich zu clustern oder steile Gradienten zu bilden. Die natürliche Datenstruktur für ein solches System ist ein Baum, in dem ein Knoten auf grober Ebene 2^n Kindknoten auf einer verfeinerten Ebene haben kann, wobei n die Dimensionalität des simulierten Systems ist.
UPC (Unified Parallel C)
Was ist UPC?
?
Eine Erweiterung von C, die für groß angelegte parallele Maschinen mit sowohl gemeinsamem als auch verteiltem Speicher (z.B. ein Cluster von SMPs) entwickelt wurde. Typischerweise läuft ein einzelner Thread auf jedem CPU-Kern. UPC ist eine PGAS-Sprache.
Vector Lane
Was ist eine Vector Lane?
?
In einem Vektorprozessor eine Vektor-Funktionseinheit, die einem Thread zugewiesen werden kann. Der Satz aller Vektor-Lanes im Prozessor kann je nach SIMD (Vektor)-Arbeitslast einem oder mehreren Threads zugewiesen werden.
Vector Processors
Was sind Vektorprozessoren?
?
Funktionseinheiten innerhalb einer CPU oder GPU, die mehrere Datenobjekte gleichzeitig verarbeiten können. Vektoroperationen werden typischerweise durch einen speziellen SIMD-Befehlssatz initiiert, z.B. Intels SSE.
Vectorization
Was ist Vektorisierung?
?
Eine Art der Parallelisierung, bei der spezialisierte Vektor-Hardwareeinheiten oder Vektorverarbeitungseinheiten (VPUs) numerische Operationen gleichzeitig auf festen Arrays statt auf einzelnen Elementen ausführen. Siehe SIMD.
Verification and Validation (V&V)
Was bedeutet Verification and Validation (V&V)?
?
Der Prozess der Überprüfung, ob ein Softwaresystem seine Anforderungen und Spezifikationen erfüllt (Verifikation) und ob es seinen beabsichtigten Zweck erfüllt (Validierung).
Victim Cache
Was ist ein Victim Cache?
?
Ein Cache, der Blöcke speichert, die bei einer Ersetzung aus einem CPU-Cache entfernt wurden. Der Victim Cache befindet sich zwischen dem Hauptcache und dem Nachfüllpfad. Da er nur Blöcke enthält, die aus dem Hauptcache entfernt wurden, fördert er schnellere Wiederzugriffe auf Daten.
Virtual Machine
Was ist eine Virtual Machine?
?
Ein Betriebssystem und zugehörige virtuelle Hardwarekomponenten, die in Software implementiert und auf einem Hypervisor ausgeführt werden, anstatt direkt mit der Hardware zu kommunizieren.
Virtual Memory
Was ist Virtueller Speicher?
?
Eine Speicherverwaltungstechnik, die verschiedene Formen des Computerspeichers (z.B. RAM und Plattenspeicher) virtualisiert. Dies ermöglicht das Schreiben eines Programms, als gäbe es nur eine Art von Speicher, den "virtuellen" Speicher, der sich wie ein zusammenhängender, direkt adressierbarer Lese-/Schreibspeicher verhält. Die Grundeinheit des Speichers im VM ist eine Seite, deren Größe oft 4KB beträgt.
Visualization
Was ist Visualisierung?
?
Im weitesten Sinne ist Visualisierung die Kunst oder Wissenschaft, Informationen in eine Form zu transformieren, die für das Sehvermögen verständlich ist. Visualisierung ist im Allgemeinen mit der grafischen Darstellung in Form von Bildern (gedruckt oder Foto), Arbeitsstation-Anzeigen oder Video verbunden.
Viterbi Algorithm
Was ist der Viterbi-Algorithmus?
?
Ein dynamischer Programmieralgorithmus zur Bestimmung der wahrscheinlichsten Sequenz nicht beobachtbarer Zustände, die zu einer Sequenz beobachteter Ereignisse führen. Die häufigste Anwendung findet er in Hidden-Markov-Modellen (HMMs).
VLIW (Very Long Instruction Word)
Was ist VLIW?
?
Eine Prozessorarchitektur, die darauf ausgelegt ist, die Befehlsparallelität auf der CPU-Ebene zu erhöhen, indem lange Befehle ausgegeben werden, die mehrere Operationen umfassen, eine Operation für jede Ausführungseinheit in der CPU.
Warp
Was ist ein Warp in der NVIDIA GPU-Architektur?
?
Eine Gruppe von Threads, die als Einheit geplant werden können, mit einer typischen Größe von 32. Alle Threads in einem Warp laufen auf demselben Streaming Multiprocessor (SM).
Word
Was ist ein Word in der Computerarchitektur?
?
Der Speicher, der benötigt wird, um eine Zahl zu speichern. Für Gleitkommazahlen ist ein einzelpräzises Word typischerweise 4 Bytes groß. Ein doppelpräzises Word (oft als Doppelword bezeichnet) ist 8 Bytes groß.
Workflow
Was ist ein Workflow?
?
Eine vordefinierte Abfolge von
Cuda Block
In CUDA-Programmierung beziehen sich blockDim, blockIdx, threadIdx und verwandte Begriffe auf die Organisation von Threads und Blöcken auf der GPU. Hier sind die spezifischen Definitionen:
blockDim
blockDim ist eine dreidimensionale Struktur, die die Dimensionen eines Blocks angibt. Jeder Block ist eine Gruppierung von Threads und blockDim gibt die Anzahl der Threads in den x-, y- und z-Dimensionen innerhalb dieses Blocks an. Es wird oft als blockDim.x, blockDim.y und blockDim.z referenziert.
blockIdx
blockIdx ist ebenfalls eine dreidimensionale Struktur, die die Position eines Blocks im Gitter (Grid) angibt. Jeder Grid besteht aus mehreren Blöcken, und blockIdx gibt den Index eines bestimmten Blocks in den x-, y- und z-Dimensionen an. Es wird oft als blockIdx.x, blockIdx.y und blockIdx.z referenziert.
threadIdx
threadIdx ist eine dreidimensionale Struktur, die die Position eines Threads innerhalb eines Blocks angibt. Jeder Block besteht aus mehreren Threads, und threadIdx gibt den Index eines bestimmten Threads in den x-, y- und z-Dimensionen an. Es wird oft als threadIdx.x, threadIdx.y und threadIdx.z referenziert.
Beispielerklärung
In dem gegebenen Code-Snippet:
i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
j = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y
werden i und j wie folgt berechnet:
-
i:cuda.blockIdx.xgibt den Index des aktuellen Blocks in der x-Dimension an.cuda.blockDim.xgibt die Anzahl der Threads pro Block in der x-Dimension an.cuda.threadIdx.xgibt den Index des aktuellen Threads innerhalb seines Blocks in der x-Dimension an.
Der Ausdruck
cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.xberechnet den globalen Indexides Threads in der x-Dimension. -
j:cuda.blockIdx.ygibt den Index des aktuellen Blocks in der y-Dimension an.cuda.blockDim.ygibt die Anzahl der Threads pro Block in der y-Dimension an.cuda.threadIdx.ygibt den Index des aktuellen Threads innerhalb seines Blocks in der y-Dimension an.
Der Ausdruck
cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.yberechnet den globalen Indexjdes Threads in der y-Dimension.
Zusammengefasst ermöglichen diese Indizes die eindeutige Identifizierung jedes Threads in einem multidimensionalen Grid auf der GPU, wodurch eine koordinierte parallele Verarbeitung von Daten ermöglicht wird.
Checklist
Threading
Use threading when:
- Your program is I/O-bound, such as reading/writing files or network operations.
- You need to run multiple tasks concurrently within a single process.
- Tasks are lightweight and involve a lot of waiting (e.g., waiting for I/O operations to complete).
- You are working in a language that supports the Global Interpreter Lock (GIL) like Python, and your tasks are mostly I/O-bound, not CPU-bound.
- You want to share memory between threads easily.
Multiprocessing
Use multiprocessing when:
- Your program is CPU-bound and requires multiple CPU cores to perform heavy computations.
- You need to bypass the Global Interpreter Lock (GIL) in Python for CPU-bound tasks.
- Tasks are independent and do not need to share memory frequently.
- You want to leverage multiple cores of the CPU for parallel execution.
CUDA (General)
Use CUDA when:
- You have data-parallel tasks that can be efficiently processed on a GPU.
- Your application involves heavy numerical computations, such as linear algebra, deep learning, or scientific simulations.
- You need significant speedups over CPU implementations.
- You have experience with or are willing to learn CUDA programming.
CUDA Streams
Use CUDA Streams when:
- You need to overlap computation and data transfers to/from the GPU.
- You want to run multiple kernels concurrently to maximize GPU utilization.
- You have multiple independent tasks that can be executed in parallel on the GPU.
- You want to reduce latency by running different operations in parallel.
HPC (General)
Consider HPC techniques when:
- You are dealing with very large datasets that cannot be processed on a single machine.
- Your computations require more resources than a single machine can provide (memory, CPU/GPU power, etc.).
- You need to run simulations or analyses that take a long time to complete on a single machine.
- You have access to a high-performance computing cluster or supercomputer.
MPI (Message Passing Interface)
Use MPI when:
- You need to run parallel programs across multiple nodes in a distributed system.
- Your tasks involve significant communication between nodes.
- You are working with a distributed memory system.
- Your application requires scalability to a large number of processors.
OpenMP
Use OpenMP when:
- You are developing shared-memory parallel applications.
- Your tasks involve parallel loops or sections that can be easily managed by compiler directives.
- You want a simpler model for parallel programming within a single node or multi-core processor.
Profiling and Optimization
- Use profiling tools to identify bottlenecks in your code.
- Optimize critical sections of your code for better performance.
- Consider using libraries like Intel MKL, cuBLAS, cuDNN, etc., for optimized mathematical operations.
Vectorization
- Use vectorization to take advantage of SIMD (Single Instruction, Multiple Data) capabilities of modern CPUs.
- Optimize loops to process multiple data points simultaneously.
Hybrid Programming (MPI + OpenMP/CUDA)
- Use hybrid programming models when you need to leverage both distributed memory and shared memory parallelism.
- Combine MPI for communication between nodes and OpenMP or CUDA for parallelism within a node.
General Best Practices
- Always start by profiling your application to understand where the bottlenecks are.
- Choose the right tool or technique based on the nature of your task (CPU-bound vs. I/O-bound, data-parallel vs. task-parallel).
- Test your parallel code thoroughly to ensure correctness and efficiency.
- Use existing libraries and frameworks that are optimized for high-performance computing whenever possible.
- Continuously monitor and tune the performance of your application as you scale up.
This checklist should help you determine the appropriate parallel computing techniques and tools to use based on the specific requirements and characteristics of your tasks.